

Title: Materials Synthesis Insights from Scientific Literature via Text Extraction and Machine Learning
Authors: Edward Kim, Kevin Huang, Adam Saunders, Andrew McCallum, Gerbrand Ceder, and Elsa Olivetti
Year: 2017
Journal: Chemistry of Materials
The sheer volume of publications makes scientific literature a vast sea of information that cannot be understood by one person. Skimming through papers and reading reviews that summarize multiple reports can help, but how can we make understanding literature more efficient? The authors of this paper present the idea of handling scientific reports the same way data scientists handle big data. They make efforts to create a better method of extracting the information in scientific papers by using machine learning techniques to analyze reported syntheses.
Automate the Mundane (Lit Research)
The authors set out to determine links between synthesis conditions and materials produced. They focus on metal oxides synthesis, which is an important and relatively well understood system. The researchers use application programming interfaces (APIs), basically an automated literature search, to find papers related to metal oxides synthesis. These papers are then “read” with a natural language processing (NLP) script to extract details of synthesis and create a database of synthetic conditions. This database is mined to develop trends and useful correlations. The API search used is through CrossRef which uses keywords related to the desired material (metal oxides in this case). The individual paragraphs within the papers found are then read and represented as mathematical objects (vectors) based on the number of important keywords. A classifier then determines if the paragraph is related to synthesis or not, based on the number of keywords found. These paragraphs are transformed into tree tables (like a multiplication tree) with the root of the tree being the type of synthesis. In the case of oxide synthesis, this is either hydrothermal or calcination reactions. The branches are then made up of experimental conditions and results including temperature, reaction time, number of atoms in the structure, and structural characterization (bulk or nano). The combination of these trees for one data set on metal oxide synthesis is presented in graphical form in Figure 1. This figure represents an amount of data which is close to the number of reaction conditions a single researcher could produce in a career. It incorporates 12913 publications, which is a little over a publication a day for 30 years.
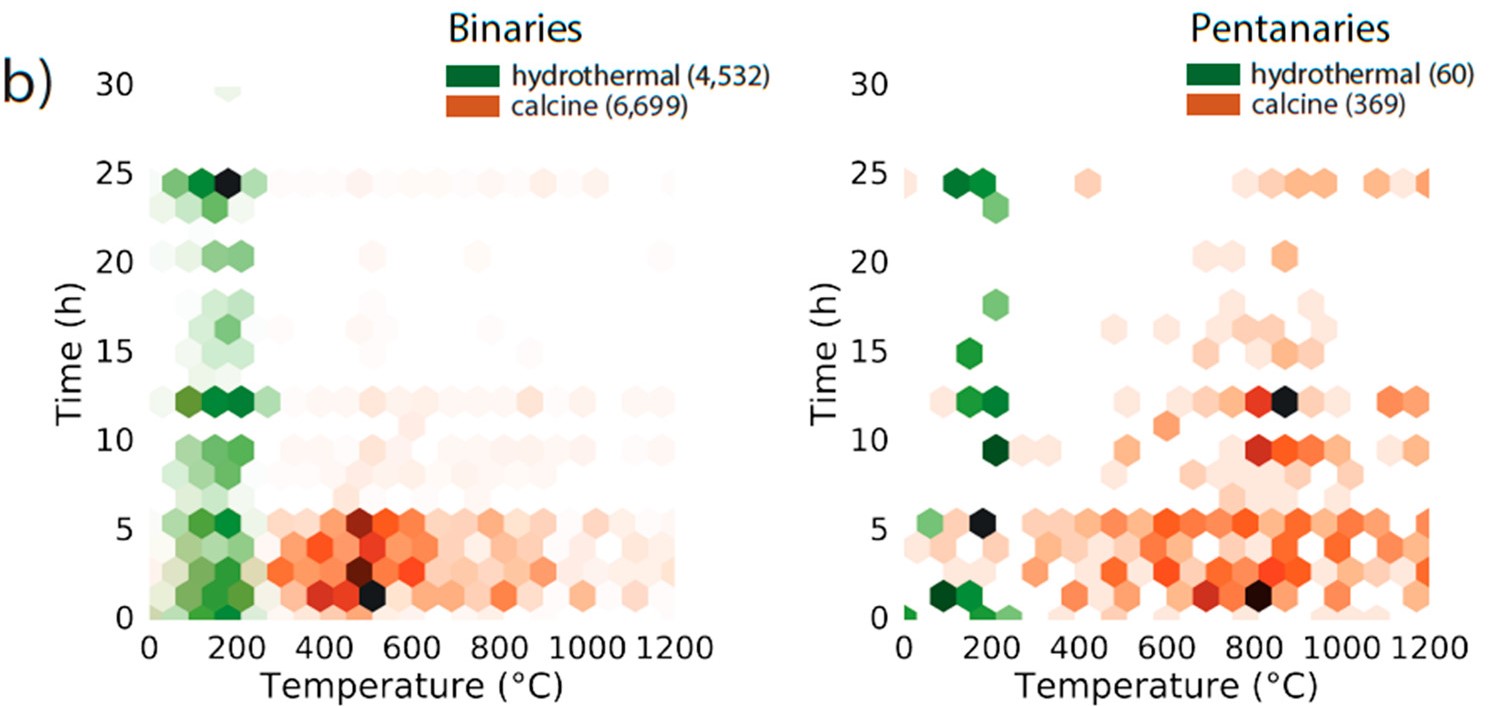
We can see highly reliable trends in these plots based on the large number of trials. The trend the authors point out is that the non-binary compounds (compounds multiple types of atoms, like K-Na bismuth titanate) require higher temperatures to form relative to their simpler binary counterparts. While this is an expected and generally accepted conclusion, the fact that a plot generated by computers sifting through literature can show the same correct trends is very cool.
Which Conditions Determine Shape?
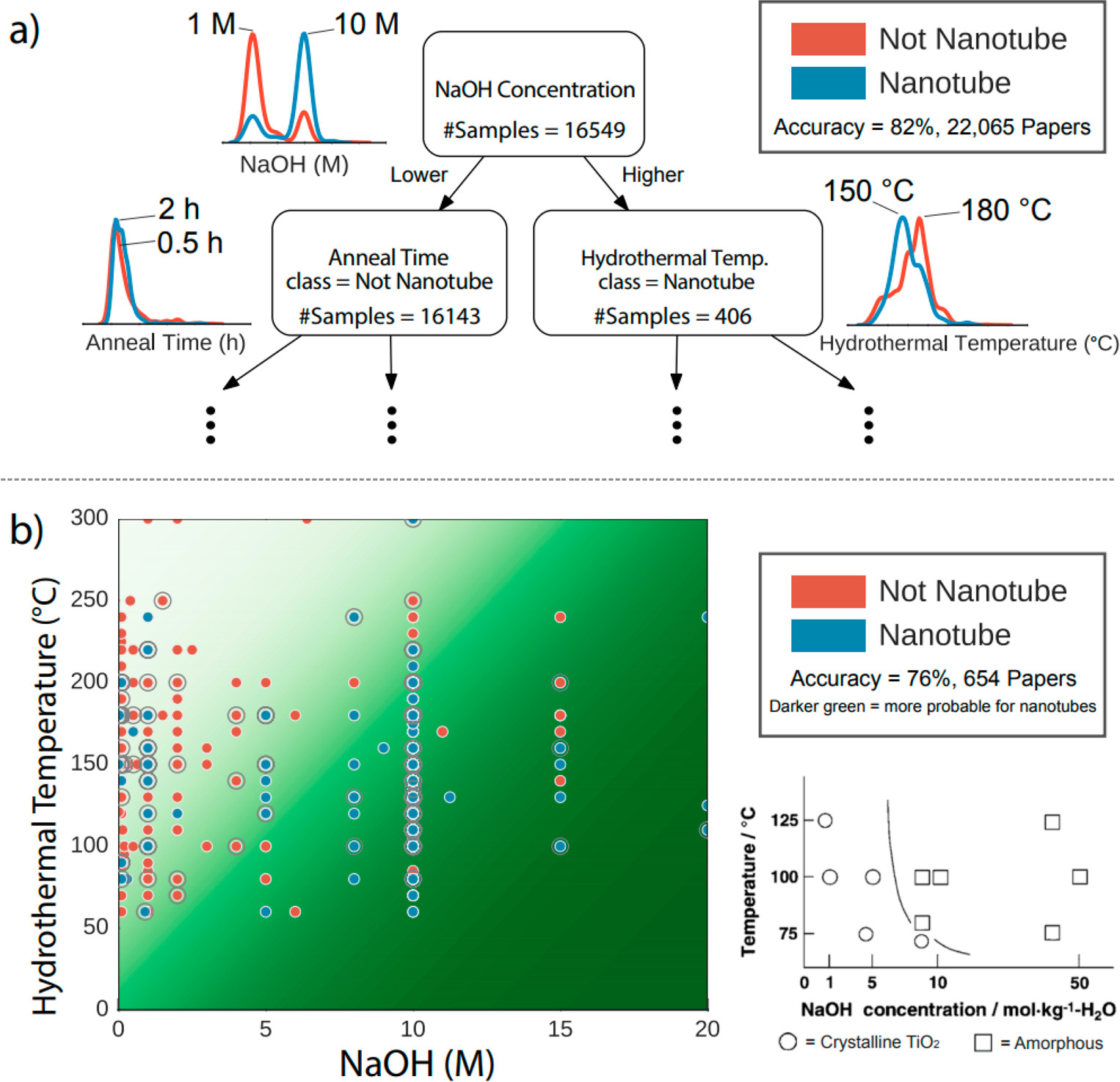
The researchers didn’t stop at these simple conditions. They applied their methods to the synthesis of titania nanotubes. Commonly controlled variables such as temperature, annealing time, and sodium hydroxide (NaOH) concentration were analyzed. Figure 2 shows that lower concentrations of sodium hydroxide, and subsequently sodium ions, favors nanotube formation over the fomation of bulk titania. Their results are again expected, since we know the mechanism for titania nanotube formation requires only a small amount of sodium ions, but this correct conclusion was corroborated by a computer program analyzing literature. This same method can be applied to synthesis conditions for lesser developed materials and discover big trends.
THE FUTURE OF DATA
These techniques will be applied to the synthesis of more interesting, and less understood, systems. We could use these learning techniques on materials that are currently too expensive to produce at market prices, such as graphene synthesis, and look for generalized trends that have not yet been recognized as a trend. The researchers present a public website with their database and insights at www.synthesisproject.org, which will hopefully grow as more researchers recognize the importance of machine learning techniques to find trends in literature.