
Title: Molecular computing: paths to chemical Turing machine.
Authors: Shaji Varghese, Johannes A. A. W. Elemans, Alan E. Rowan and Roeland J. M. Nolte
Year: 2015
Journal: Chemical science
http://pubs.rsc.org/en/content/articlelanding/2015/sc/c5sc02317c#!divAbstract
What is the weather today? Is it sunny or is going to rain or even snow?
For many, the day begins with a quick glance at the weather forecast. But have you ever imagined how the weather forecast is possible?
Weather forecasting is a problem that involves many atmospheric variables, which makes it hard to solve. These complicated problems are either extremely hard or not solvable analytically, so they are often solved using computational methods. One may think that such problems are rare and are limited to highly sophisticated scientific activities but the truth is that such problems surround us. Just like weather forecast, these hard problems are an integral part of smartphone’s functioning, flight schedules, online shopping, and national security issues. Considering their widespread nature, we are in constant need of state-of-the-art computing methodologies to solve them.
A machine does computing for us by following step-by-step instructions which are given to it. These set of instructions written by human beings are called algorithms and it involve the use of numerical, algebraic and stochastic tools. Essentially, we map out a plan for solving a problem but given the extent and the nature of problem we implement machines to solve it for us. This computational strength of a machine depends on its ability to store and process information.
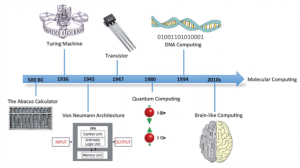
The idea of computing by a machine was first proposed by Alan Turing in 1936. The Turing machine had infinitely long tape that can read and write symbols by moving forward and backward along the tape. Each symbol on the tape is a piece of information which the machine access according to the algorithm and generates result.
Different computational technologies have been built based on derivatives of the Turing machine concept. However, a plateau is foreseen in the near future for the existing computing machines due to the space available to store information. Current technology uses silicon chips to store information and storing more information on a chip of a particular size requires miniaturization of the components. Even though the advent of nanotechnology has led to tremendous progress in overcoming the miniaturization challenge, we are fast approaching the limiting value.
Figure 1 shows the evolution of computing technology. Increasingly our computing designs are inspired by biological systems to improve the computing abilities of machines. A long-term solution to the fast approaching crisis of space saturation can be solved by designing molecular machines. These systems can store, modify and customize information at molecular level and provide more levels of information than just the binary codes 0 and 1. The current silicon based computing technology can increase its computing strength by increasing the number of components on the chip. However, no matter how much we reduce the size of components we will still be storing information in binary codes. This limits the levels and potential complexity of information processing. In molecular machines, this limitation can be overcome due to molecules having more than two states to store information within.
Molecular computing is also inspired from biology. The cells present in living organisms process information and perform functions like digestion that keep us alive. Our physical resemblance with our parents is also a consequence of information processing by molecular machines present in our cells. These molecular machines are called DNA and RNA. They store and transfer information coded in your parents’ bodies to you. There is a striking resemblance between the Turing machine architecture which was proposed at the beginning of the computing era and these naturally occurring machines in our body. Although numerous computing technologies have evolved from Turing machine concept, there is still no functioning machine in the style of the initially proposed Turing machine blueprint. A lot of research is going on to finally combine the abstract idea of Turing machines and molecular machines to build “Molecular Turing Machines.”
We will discuss one such design which uses a catalyst and a polymer chain to form a chemical Turing machine. Before diving into the working of this machine, let’s briefly understand polymers and catalysts. A polymer is a large molecule that is made up of repeating sub-units called monomers. One of the most commonly used polymers is polyethylene terephthalate (PET) which is used to make plastic bottles and containers. Catalysts are molecules that increase the rate of a reaction without itself undergoing any chemical change. Most industrial reactions use catalysts to improve the reaction rates and obtain products more efficiently and faster.
In the system discussed, the polymer polybutadiene is used as the base chain which stores information in terms of its molecular state as shown in Figure 2.
The polubutadiene polymer has double bonds which are oxidized to form epoxides by the catalyst. The double bond state has no oxygen atom and epoxides contain oxygen.
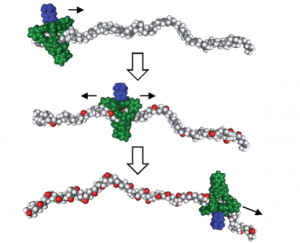
The oxygen atoms in the polymer chain are used as signature of the molecular state. The presence of oxygen atom can be seen as 1 and absence of oxygen atom can be seen as 0 giving binary codes for information storage and processing. A manganese porphyrin-based cage compound acts as a ring-like catalyst which is bound to this polymer chain and can move along it, as shown in Figure 2.This catalyst is responsible for changing the molecular state and thus processing information. Functioning of this polymer-catalyst system is called “processive catalysis” because the polymer chain undergoes changes as the catalyst moves. So, based on a given algorithm, the catalyst can move and process information. From this study, it is clear that there are two primary conditions to make a working computing machine from a polymer-catalyst system. First, the catalyst should be able to clamp/ attach to the polymer chain such that it can move along it. Usually ring-like catalysts are suitable as they can surround and glide along the chain.
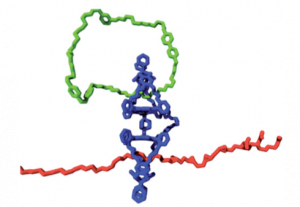
And second, there should be at least two different molecular states present as the catalyst works to identify as storage levels. In the given example, we had only two possible states. However, presence of more functional groups in the polymer chain that can be selectively modified by catalyst can give multiple levels of information. Figure 3 shows a general blueprint of catalytic molecular Turing machine.
Biological systems are replete with examples of molecular machines used for functioning and survival of living organisms. Inspired from these existing natural molecular machines, research is underway to apply them in computing technology. Their ability to provide multiple information levels and higher information space can enable us to overcome the challenges of existing computing technology.