
Featured Image from skeeze on Pixabay
Yuichiro Koide, Ryosuke Kojima, Kenjiro Hanaoka, Koji Numasawa, Toru Komatsu, Tetsuo Nagano, Hisataka Kobayashi & Yasuteru Urano
Published in Communications Chemistry, 2019
Communications Chemistry is an Open Access Journal with the Nature Publishing Group
To be able to understand disease we need to understand what is happening in every cell of your body and unfortunately,it’s not as simple as asking them how they’re feeling – they’re not very good at communicating their emotions. To try and understand what is going on at a molecular level, scientists have developed thousands of different probes or indicators that can be administered to a sample of cells, and provide a readout that tells you something about the cellular environment and consequently “how they’re feeling”.
Cancerous cells are often stressed indicated by low oxygen and a highly acidic environment compared to healthy cells. A reactive dye, that changes its fluorescence profile when it encounters a particular environment, can be added to a cell sample to “ask” the cells what state they’re in. The fluorescence is detected by instruments such as a UV-Vis spectrophotometer or fluorescence microscope which are pretty common pieces of kit in a chemical biology lab.
This technique doesn’t allow interrogation of cells that are deep in a piece of tissue as UV light doesn’t penetrate tissue well. Also, there are a large number of components within every cell that naturally fluorescence (termed autofluorescence) which sometimes make it difficult to distinguish the fluorescence native to the cell from the florescence of the probe. Not to mention that irradiation of cells with UV/Visible range of light to first excite the fluorophore and “ask” it what state it is in can be detrimental cell health.
Instead, radioactive isotopes are often used in these applications (think PET imaging ), but this also has downsides – a major one being safety hazards of extended exposure to radioactive compounds and also that it requires specialised equipment to detect the output. So, we need a compromise – a sensitive probe that can be interrogated deep below the tissue surface by using standard equipment.
This is where IR-detectable probes come in, infrared (IR) light has a longer wavelength (lower energy) than UV light and hence is able to penetrate tissue more deeply and less destructively. The Urano group have taken a new approach to designing such a probe – they started with a fluorophore named hydroxymethyl tetramethylrhodamine (HM-TMR) which undergoes a conformational change (cyclisation) depending on the pH (acidity) of the environment (Figure 1, top). HM-TMR is fluorescent when irradiated with light in the UV/Vis range and the pH is below 9.6 resulting in protonation of one of the amine groups. Above pH 9.6 the amine deprotonates, allowing a spiro-cycle to form thereby switching off the fluorescence (Figure 1). However this change occurs well outside the pH range that is observed in biology (pH ~5-8). They hypothesised that by substituting the oxygen atom in the tricyclic xanthene structure for a silicon, selenium or germanium atom (all from group 14) (Figure 1, bottom) the cyclisation event (and the ability to fluorescence) would shift to a lower pH, and the probe would instead be excited in the IR range (not the UV/Visible).
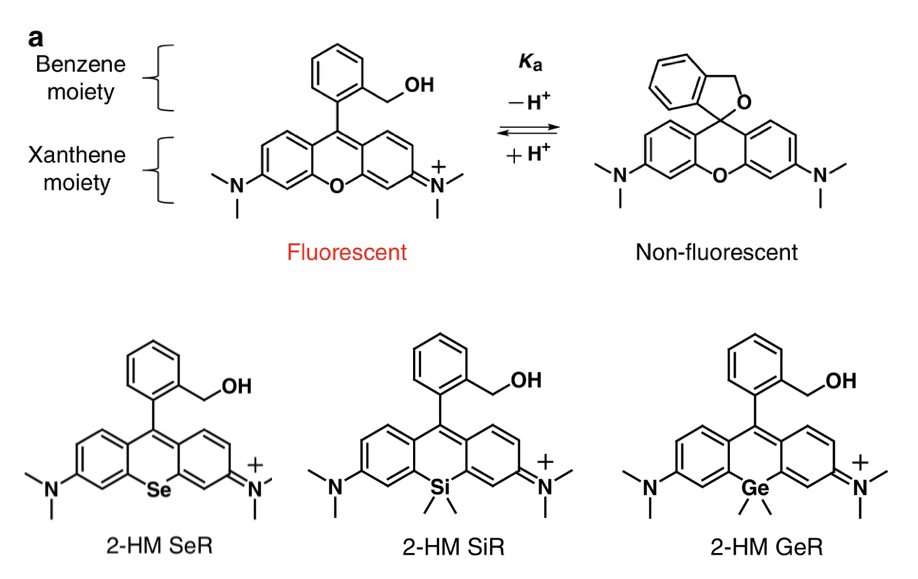
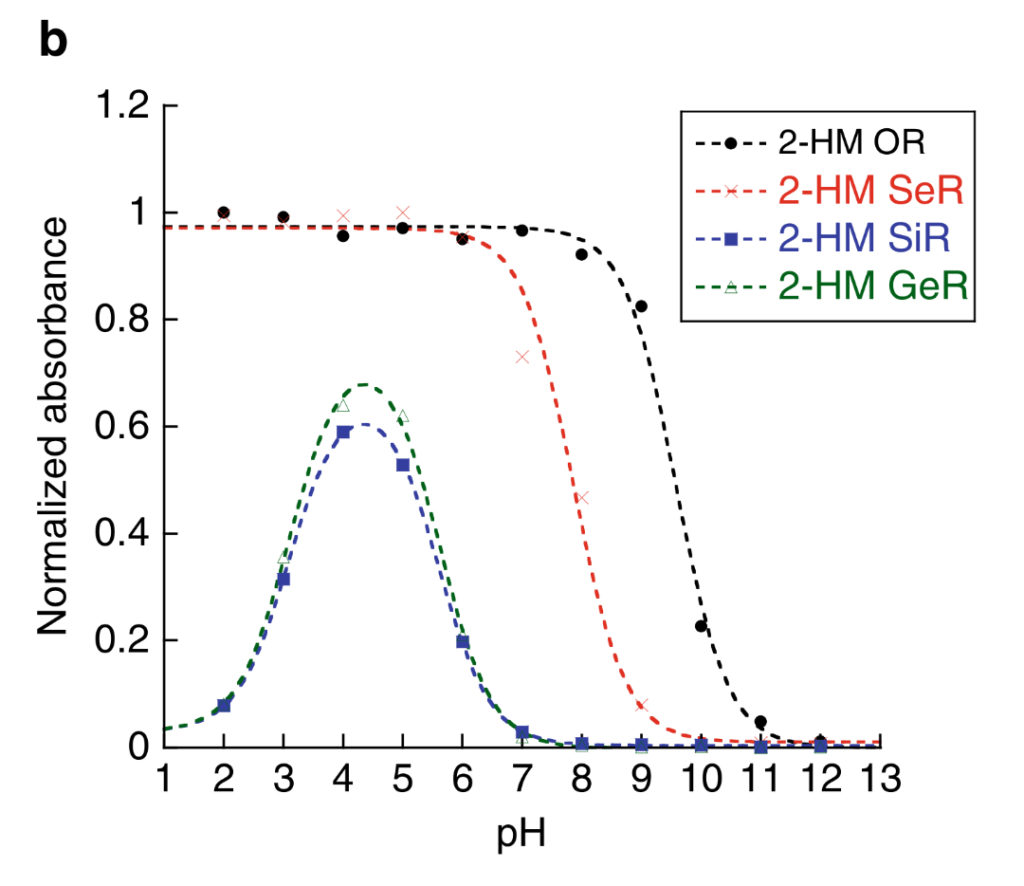
They were correct! Mostly. All three new fluorophores only began to fluoresce at a lower pH and excited at a longer wavelength. The selenium analogue (HM-SeR) was the most similar to the original HM-TMR, whereas the silicon (HM-SiR) and germanium (HM-GeR) analogues were excited at over 600 nm, and cyclised at pH ~5.7 which would be more useful to investigate biological environments. However, the both the HM-SiR and HM-GeR re-cyclised (non-fluorescent) at very low pH (Figure 2), and not all of the molecules were switched/cyclised at any given pH which would make measuring the true extent of the true pH difficult. The question was posed – what else can we change to overcome this problem?
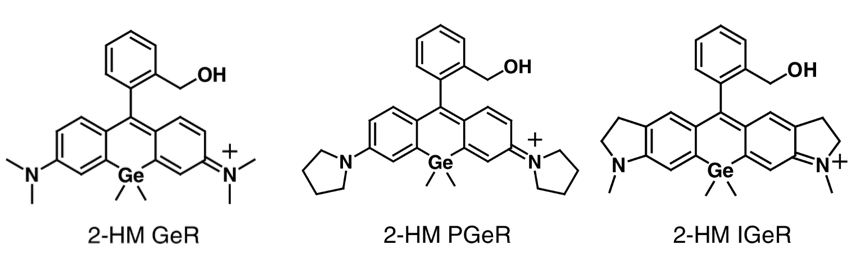
They envisioned switching the dimethyl-amino groups with cyclic-aminos wouldn’t affect near-IR fluorescence or pH sensitivity, but may restrict the re-cyclisation event at low pH as cyclic amines are more difficult to protonate. Two new GeR analogues were synthesised (HMPGeR and HMIGeR, Figure 3) and indeed, these modifications resulted in full switching of the fluorescence below pH 6.6 and 5.5 respectively.
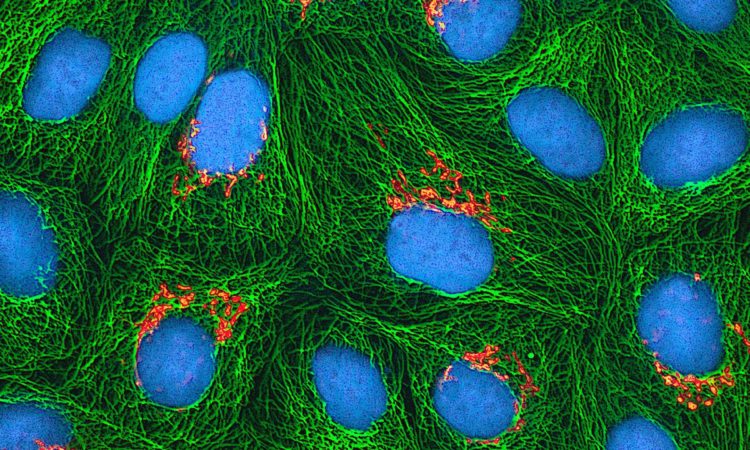
Now with a winner in hand, it was time to show this worked in a biological setting. First, the probes were tested in cells. HMIGeR was first attached to a protein, Herceptin, known to be bind the HER2 receptor (important in breast and ovarian cancer) and internalised. The Her-HMiGeR conjugate was not observed (as it wasn’t fluorescent) until it was in the cell, shown in clusters, indicating that it was taken up and captured in acidic vesicles referred to as lysosomes where the low pH switched the fluorescence on. Conversely, the same protein tagged with a pH independent GeR fluorophore, only showed a sea of colour as the fluorescence was always ‘on’ and therefore didn’t provide any biological information. They demonstrated the HER2 receptor was responsible for uptake by repeating the experiment but with a drug known to instead block HER2 and saw no significant fluorescence response, indicating the protein was not internalised and trapped in lysosomes as it was before.
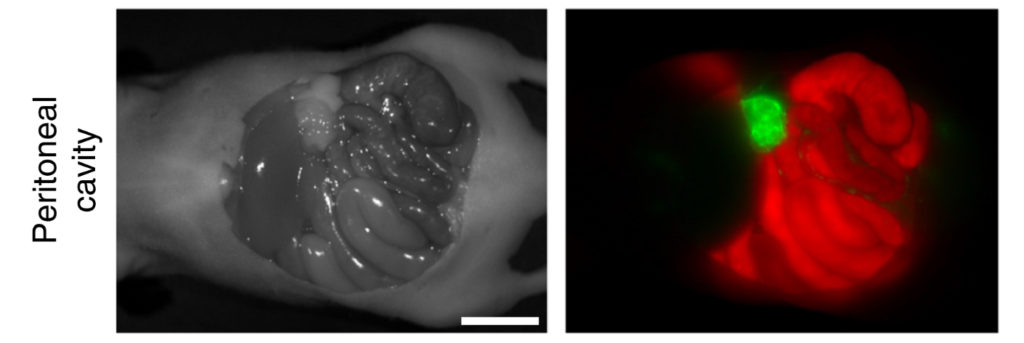
A similar experiment was conducted in mice which had discrete tumours. When administered with the Her-HMIGeR conjugate it showed a clear fluorescent signal where the tumours were located, as the pH probe was switched on owing to the low pH environment (Figure 4). Most importantly, this near IR signal was clearly distinguishable from the natural auto-fluorescence of the surrounding tissue and clearly defines the tumour. Technologies like this are important to develop tools that allow surgeons to confidently identify and excise tumours and ensure they have not left any traces behind.
This study is a great example of how understanding the design of a chemical can allow a rational design of a probe to study biological events important in disease. Read the full article to understand in more detail the chemical reasons for their design.